
What If GROUP BY Could Think?
DuckDB is great at aggregating numbers. SUM, AVG, COUNT —
these work on structured data. But what about thousands of free-text reviews?
We built aggregate functions that call Claude during the GROUP BY. Text goes in, structured intelligence comes out:
SELECT month, qf_llm_summarize( review_text, 'Analyze for the owner. Return JSON with momentum, strengths, issues, actions.' ) FROM reviews GROUP BY month;
That's it. 133 months of reviews → 133 structured analyses with scores, severity-rated issues, and action items. Each month's reviews get accumulated, then Claude reads them all and produces a JSON assessment.
The Hard Part: 700 Labels, One Taxonomy
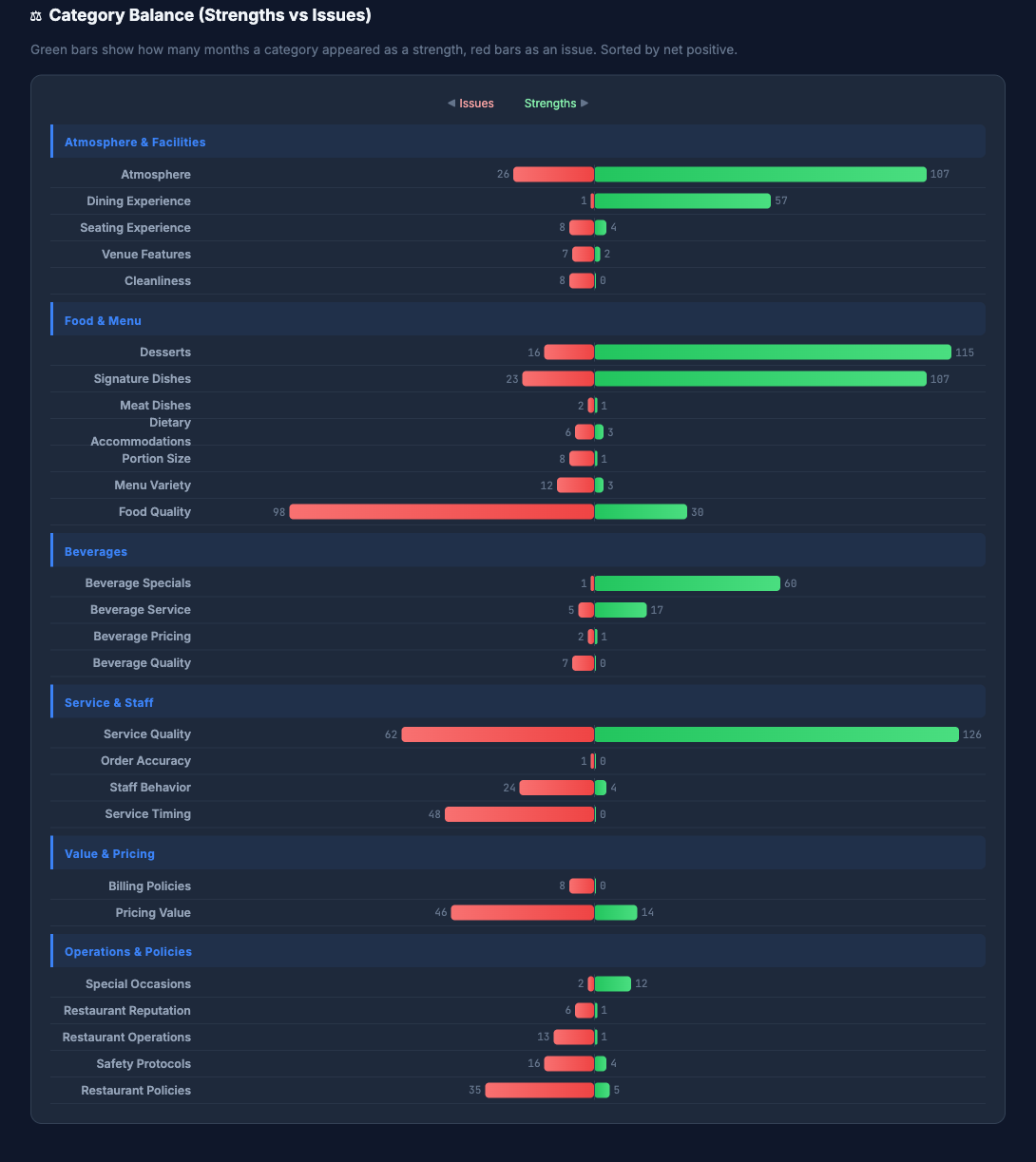
When you ask an LLM to categorize 133 months of reviews independently, you get ~700 unique labels. "weekend-brunch-slow-pacing", "brunch-service-delays", "sunday-brunch-understaffed" — all the same issue.
Our second aggregate function, qf_llm_distill, fixes this in one call:
SELECT qf_llm_distill(label, [30, 6]) FROM all_labels;
700 labels → 30 categories → 6 themes. Every label mapped. The function chunks, normalizes, consolidates, and validates internally — re-submitting any labels the LLM missed, merging groups that overshoot the target.
The Pattern
It's the same mechanism at every level. Reviews become summaries. Labels become categories.
Categories become themes. GROUP BY handles the structure,
the LLM handles the meaning.
SQL already knows how to group data. Now the LLM knows how to make sense of each group.
Under the Hood
See the Python behind qf_llm_summarize
class SummarizeFunction(AggregateFunction[SummarizeState]): class Meta: name = "qf_llm_summarize" def update(cls, states, group_ids, text, prompt): # Accumulate text. No LLM calls. for i in range(len(group_ids)): s = states[group_ids[i].as_py()] states[gid] = SummarizeState( texts=s.texts + "\n---\n" + text[i].as_py(), prompt=prompt[i].as_py(), ) def combine(cls, source, target, params): # Merge parallel workers return SummarizeState( texts=target.texts + "\n---\n" + source.texts) def finalize(cls, group_ids, states, params): # Call Claude — once per group results = [] for gid in group_ids: s = states[gid.as_py()] resp = anthropic.Anthropic().messages.create( model="claude-sonnet-4-20250514", messages=[{"content": s.prompt + s.texts}]) results.append(resp.content[0].text) return pa.record_batch({"result": pa.array(results)})
DuckDB handles GROUP BY, parallelism, and memory. Your Python just defines what happens to each group.
See the full pipeline
Step 1: DuckDB reads 5GB of Yelp JSON, samples 20 reviews per month → Parquet
Step 2: GROUP BY month + qf_llm_summarize → 133 structured JSON analyses with momentum, severity-rated strengths/issues, and action items
Step 3: qf_llm_distill(label, [30, 6]) → one SQL call turns ~700 messy labels into a 3-level taxonomy (labels → 30 categories → 6 themes), with validation ensuring every label is mapped
Step 4: Jinja2 renders the HTML dashboard from the JSON. Total: ~$3, ~150 LLM calls.
How qf_llm_distill validates every label is mapped
After each level, the function checks: did every input get a mapping? If labels were skipped, it re-submits just the missing ones with the existing categories as context. If there are too many groups, a consolidation pass merges the smallest. After 3 repair attempts, unmapped items go to "other" with a warning. The guarantee: every input label has a complete path through all levels.